
今天花了点时间把 LiteLLM 网关的模型分流策略彻底梳理了一遍,记录一下整个思路和最终配置。
为什么需要模型分流
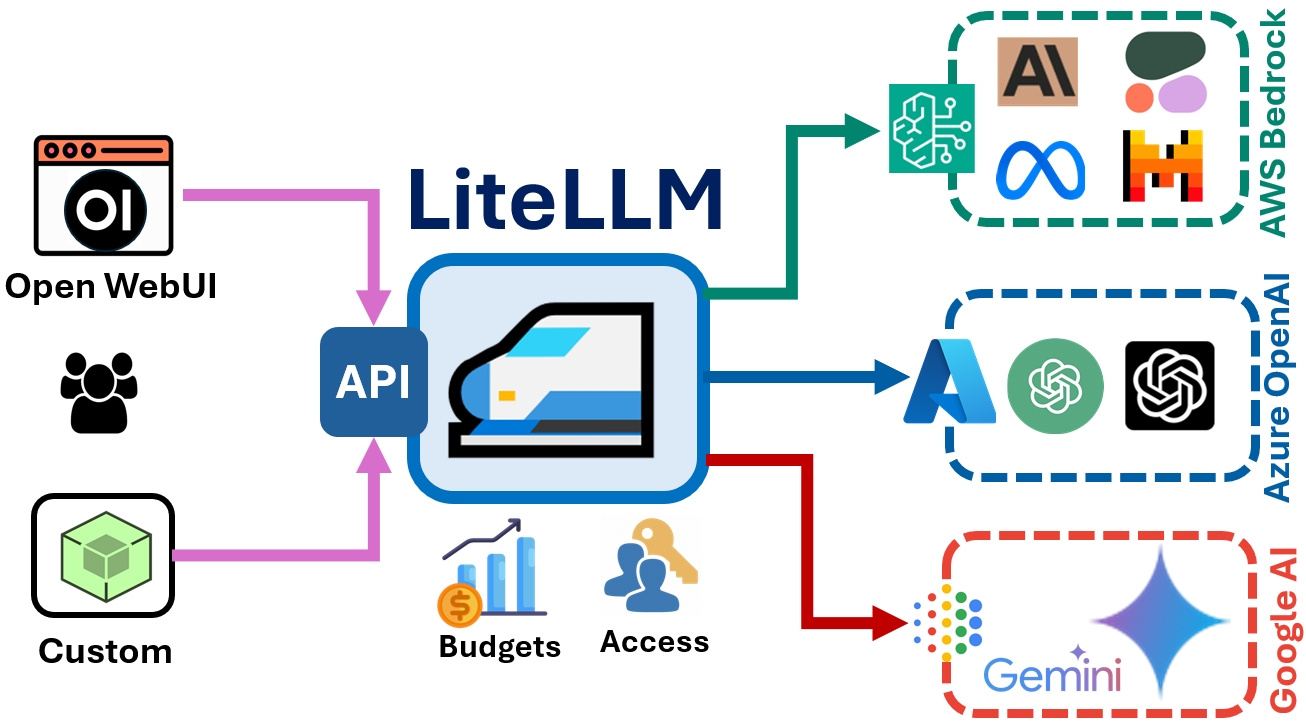
我的 AI 基础设施是这样的:
Telegram → Hermes → LiteLLM 网关 → 各模型LiteLLM 作为统一网关,对外暴露一个 OpenAI 兼容接口,后端接了十几个模型。Hermes 只需要知道 ai.XXX.com 这一个地址,不需要关心底层用的是哪个模型。
这样做的好处是:模型随时可以替换、升级、切换,Hermes 完全无感知。
模型池构成
最终配置了以下模型:
付费模型(按量计费,极低成本)
- DeepSeek V3 — 中文最强,输入 $0.27/百万 token,性价比极高
- Gemini 3 Flash — Google 最新快速模型,支持多模态,免费额度充足
- Gemini 3.1 Pro — 强推理,限速时作为 Pro 级备用
NVIDIA NIM 免费模型
meta/llama-3.3-70b-instruct— 通用英文主力minimaxai/minimax-m2.5— 中文能力强moonshotai/kimi-k2.5— 推理能力强z-ai/glm5— 中文备用(后因超时替换为 OpenRouter 版本)
OpenRouter 免费模型池(最终保底)
minimax/minimax-m2.5:freez-ai/glm-4.5-air:freemeta-llama/llama-3.3-70b-instruct:freenvidia/nemotron-3-super-120b-a12b:free
按需付费高端模型
- Claude Sonnet 4.6 — 通过 OpenRouter 接入,$3/$15 每百万 token,顶级推理备用
最终 Fallback 链路
yaml
fallbacks:
- gemini-flash:
- deepseek
- llama-3.3
- openrouter-free
- gemini-pro:
- deepseek
- openrouter-free
- deepseek:
- llama-3.3
- openrouter-free
- minimax:
- glm-5
- llama-3.3
- openrouter-free
- glm-5:
- llama-3.3
- openrouter-free
- kimi:
- llama-3.3
- openrouter-free
- llama-3.3:
- openrouter-free
- sonnet:
- deepseek
- openrouter-free任何模型失败,都有完整的降级链路,最终由四个免费模型轮询池兜底。
