
最近负责一个稽核规则AI生成的项目方案的编写。
在做稽核规则AI方案的时候,其实一开始我们也考虑过从底层数据、业务规则一步一步梳理上来,但很快发现这种路径效率太低,而且周期不可控。
相比之下,我们更倾向于走一条把现有稽核系统中已经沉淀下来的资产用起来,通过脚本反向生成稽核规则和字典库,相当于站在已有成果之上去做AI能力的构建,而不是从零开始重造一套体系。
把第一阶段的重点放在“存量”而不是“增量”。核心原因在于,现有的稽核脚本本身就是经过长期生产验证的结果,业务逻辑成熟、可靠性高,是最优质的一批训练数据。同时,无论是集团侧的收入保障体系,还是cBSS稽核、省内个性化稽核,这三套体系其实已经覆盖了绝大多数主流场景,短期内并不存在“数据不够用”的问题。
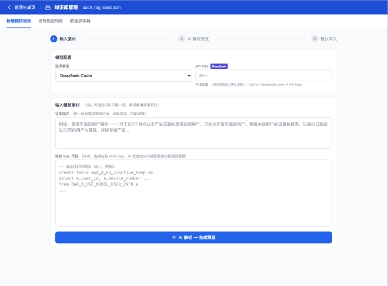
优先走“脚本 → AI解析 → 人工确认 → 入库”这一条路径,把生产环境中已经验证过的SQL脚本作为核心输入,让AI去理解和结构化这些规则,再由人工进行把关,最终沉淀成标准化的知识库。在这个基础逐步夯实之后,才考虑逐步开放自然语言直接生成规则的能力,但前提始终是结果可控、可审核、可回滚。
在这种情况下,优先把存量资产进行结构化沉淀,一方面可以快速形成一套可用的AI能力,另一方面也可以在真实业务反馈中不断修正和迭代模型能力。本质上是在用“已验证的知识”去约束AI的输出边界,从机制上规避了完全自由生成带来的“AI幻觉”问题。换句话说,我们不是让AI从零创造规则,而是让它在已有规则体系内做理解、抽象和增强,这样既保证了效率,也守住了质量底线。
