
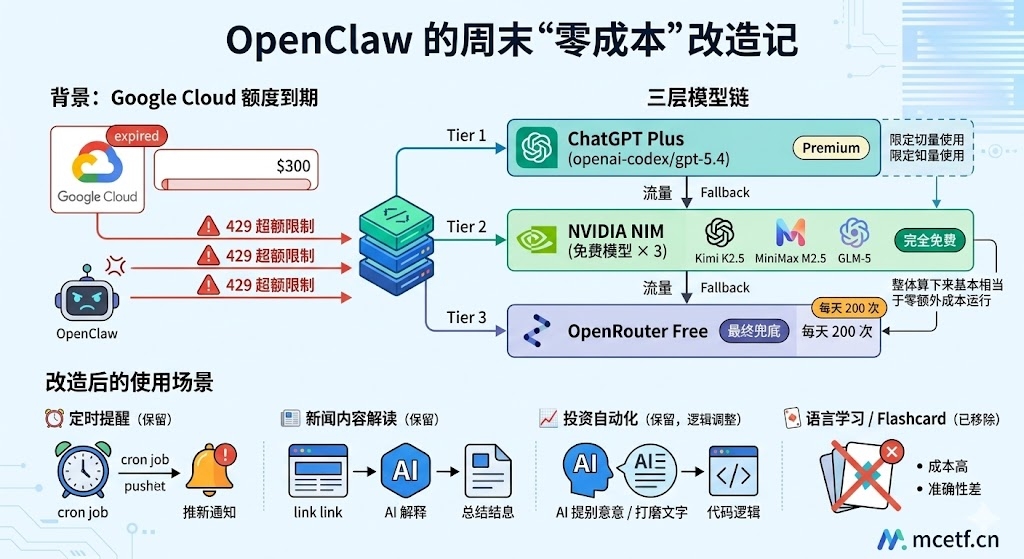
背景
这个周末花了不少时间对 OpenClaw 做了一次系统性改造。起因很简单:之前订购的 Google Cloud 300 美元免费额度到期,Gemini 的 API 调用开始大面积报 429(超额限制),bot 彻底无法回复。
需要找到一个尽可能低成本、甚至零成本的方式让系统继续跑起来。最终确定了三层模型链的方案,整体算下来基本相当于零额外成本运行。
解决方案:三层模型链
主模型:ChatGPT Plus (
openai-codex/gpt-5.4)通过低价区订阅,费用本身不高。近期语言考试在即,Codex 编码需求不多,Premium 额度消耗有限,作为日常主力模型。
中间层 Fallback:NVIDIA NIM 免费模型 × 3
引入 Kimi K2.5、MiniMax M2.5、GLM-5 三个模型。主模型额度耗尽或出现问题时自动切换,完全免费。
托底层:OpenRouter Free
openrouter/free自动从可用免费模型中选择最合适的,每天 200 次请求,作为最终兜底,无需任何费用。
关键操作记录
① NVIDIA NIM API 接入
- 前往
build.nvidia.com注册账号,生成nvapi-xxxAPI Key。 - 在
auth-profiles.json中新增nvidia:defaultprofile,写入 API Key。 - 在
models.json中新增nvidiaprovider,BaseURL 指向https://integrate.api.nvidia.com/v1。 - 将 Kimi K2.5、MiniMax M2.5、GLM-5 三个模型挂在
nvidiaprovider 下,共用同一 API Key。 - 同步更新
clawdbot.json,将三个模型加入models.providers。
② 调试过程中踩过的坑
gateway与pm2进程冲突:systemd和pm2同时管理导致端口 18789 反复被占。停掉pm2的oc-gateway后恢复正常,实际应由systemd统一管理。- 模型 ID 路由错误: 将第三方模型(moonshotai / minimaxai / z-ai)单独拆出独立 provider 会导致 404。最终统一挂在
nvidiaprovider 下,OpenClaw 的正确路由格式为nvidia/moonshotai/kimi-k2.5。 clawdbot.json不支持alias字段: 只有agents/main/agent/models.json支持别名,写入clawdbot.json会导致 config invalid,gateway 拒绝启动。openai-codextoken 过期: 通过openclaw configure重走 OAuth 流程,新 token 写入openai-codex:walker.wangw@gmail.comprofile,需手动更新lastGood字段指向新 profile。- Google Gemini 持续 429: 降格至 fallback 第 4 位,仅在前三层全部失败时触发。
③ 最终 Fallback 链
- 主模型:
openai-codex/gpt-5.4 - Fallback 1:
nvidia/moonshotai/kimi-k2.5 - Fallback 2:
nvidia/minimaxai/minimax-m2.5 - Fallback 3:
nvidia/z-ai/glm5 - Fallback 4:
google/gemini-3-flash-preview - Fallback 5:
openrouter/free
用了这么久,聊聊场景的变化
OpenClaw 在国内的热度正在迅速降温,但我倒是一直在用。只是使用场景发生了一些调整,有些功能被保留,有些被主动放弃。
⏰ 定时提醒(保留)
依然在用。包括这次也顺手设了个 cron job,在 Codex token 到期前 48 小时通过 Telegram 推送提醒。
📰 新闻内容解读(保留)
目前用得最多的场景。ChatGPT 和 Gemini 经常对长文章提示"无法阅读全文",直接把链接扔给 OpenClaw 就能完整解读,省去手动复制的麻烦。
📈 投资平台自动化(保留,逻辑调整)
通过 Telegram 推送金融信息和账户动态。决策逻辑的角色发生了根本性变化:
- 之前: 让大模型直接驱动决策。
- 现在: 大模型只负责识别意图和文字润色,所有决策策略完全由后台代码实现。
- 原因: 这样可以避免大模型因随机性产生误判,在敏感、重要的操作上保持确定性。
🃏 语言学习 / Flashcard(已移除)
这个场景被主动放弃了,原因有两层:
- 成本问题: 用大模型记单词的 Token 消耗极高,性价比远不如用同样的额度来写代码。现在改用 RemNote 做 Flashcard,支持电脑、手机、平板多端同步,速度快,体验反而更好。
- 准确性问题: 之前曾让 OpenClaw 大量补充知识点辅助学习,但由于每次调用的模型不完全一致,对同一知识点的观点和关注点会产生矛盾,导致前后逻辑冲突。大模型的随机性在记忆类任务上是硬伤——你永远不知道它今天的答案和上周说的是不是同一套。
小结
这次改造让我对大模型的使用边界有了更清晰的认识:它适合做加速器,不适合做权威源。 用它来解读、润色、推送是合适的;让它直接驱动决策或构建知识体系,风险就会被放大。零成本续命成功,继续跑着。
