
今天凌晨4点就醒来了,与其勉强继续入睡不如起来喝杯咖啡迎接英伟达的财报,全球静候英伟达的财报,以判断是不是存在AI的泡沫。
对于英伟达的预估中,很重要的一点就是NVIDIA Blackwell 是不是达到预期,财报出来前了解下什么NVIDIA Blackwell 架构吧。
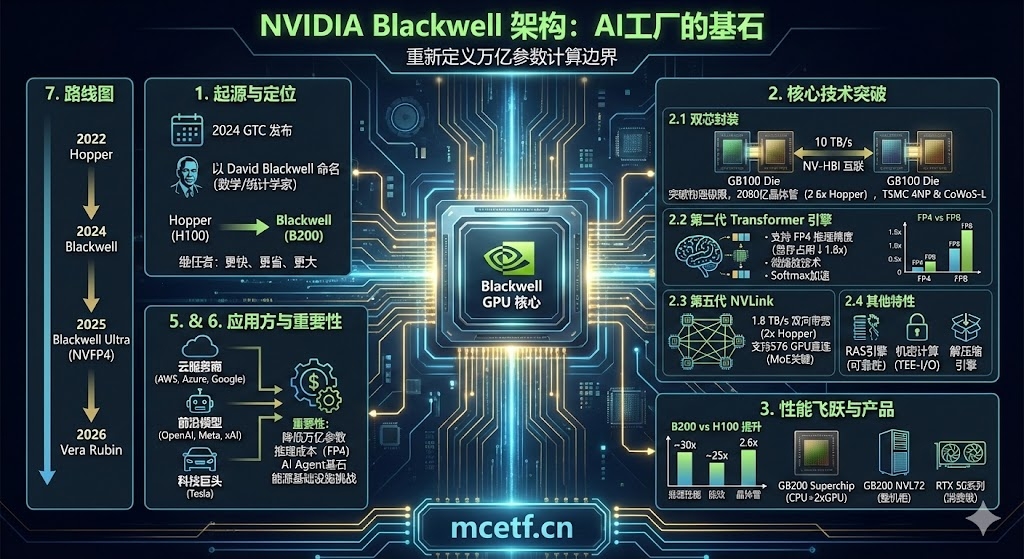
1 什么是Blackwell?
Blackwell是NVIDIA于2024年3月GTC大会正式发布的新一代GPU架构,以美国数学家、统计学家 David Blackwell 命名。他是第一位被美国国家科学院接纳的非裔美国学者,在博弈论、概率论、信息论和统计学领域做出了开创性贡献——这些领域正好是当今生成式AI的数学基石。
Blackwell是Hopper架构(H100/H200)的继任者,定位于支撑万亿参数模型的训练和实时推理。简单来说,如果Hopper是让AI大模型"能跑"的引擎,那么Blackwell就是让AI大模型"跑得快、跑得省、跑得大"的下一代引擎。
2 核心技术突破
2.1 双芯封装:突破物理极限
芯片制造有一个"光罩极限"——光刻机单次能在硅片上刻印的最大面积。上一代Hopper的GH100芯片已经接近这个极限(814mm²)。Blackwell的解决方案是:把两颗"满配"的GB100芯片通过10 TB/s的NV-HBI互联封装在一起,对外表现为一颗统一的GPU。
这意味着单颗Blackwell GPU总共拥有2080亿个晶体管,是Hopper的800亿的约2.6倍。采用台积电定制4NP工艺制造,并通过CoWoS-L 2.5D封装技术将两颗芯片放置在同一块硅中介层上。
2.2 第二代Transformer引擎
Blackwell专门为大语言模型(LLM)和混合专家模型(MoE)设计了第二代Transformer引擎。关键创新包括:
- 支持FP4(4位浮点数)推理精度:相比FP8,内存占用减少约1.8倍,同时保持接近FP8的精度,意味着同样的显存能装下更大的模型
- 微缩放(Micro-tensor Scaling)技术:通过更精细的动态范围管理,在低精度下仍能保持高质量输出
- Softmax加速:注意力层的softmax计算被硬件加速,显著提升推理吞吐量
2.3 第五代NVLink
AI训练和推理往往需要数百甚至数千张GPU协同工作,GPU之间的通信带宽直接决定了系统效率。Blackwell的第五代NVLink实现了:
- 每GPU双向带宽达1.8 TB/s,是Hopper NVLink的约2倍
- 最多支持576颗GPU之间直接互联,可在不借助外部网络的情况下进行全速通信
这对于训练万亿参数的MoE模型至关重要,因为GPU之间需要频繁交换激活信息。
2.4 其他关键特性
- RAS引擎(可靠性/可用性/可维护性):专用硬件引擎通过AI预测性维护提前识别潜在故障,保障大规模集群连续运行数周不中断
- 机密计算:行业首个支持TEE-I/O的GPU,可在不牺牲性能的情况下保护敏感数据和AI模型
- 解压缩引擎:硬件级别支持LZ4、Snappy、Deflate等压缩格式,加速数据库查询和数据分析
3 性能飞跃:Blackwell vs Hopper
下表展示NVIDIA官方公布的关键性能提升:
| 指标 | Hopper (H100) | Blackwell (B200) |
|---|---|---|
| 晶体管数量 | 800亿 | 2080亿(2.6x) |
| 推理性能提升 | 基准 | 约30x |
| 能效提升 | 基准 | 约25x |
| NVLink带宽 | 900 GB/s | 1.8 TB/s(2x) |
| NVLink GPU互联 | 最多256颗 | 最多576颗 |
| 低精度支持 | FP8 | FP4 |
用一个类比来理解:如果Hopper是一台高性能跑车,Blackwell就是同时具备跑车的速度、卡车的装载量和混动车的省油性能。
4 产品线全景
4.1 数据中心产品
| 产品 | 定位 | 典型客户 |
|---|---|---|
| B200 | 单卡加速卡,可插入HGX服务器 | 云服务商、企业 |
| GB200 | Grace CPU + 2×Blackwell GPU超级芯片 | AI工厂、超算中心 |
| GB200 NVL72 | 整机柜方案,36颗Grace CPU + 72颗Blackwell GPU | xAI、OpenAI等前沿实验室 |
| GB300 (Ultra) | Blackwell Ultra进化版,支持NVFP4 | 下一代超大规模集群 |
4.2 消费级产品
Blackwell架构也延伸到了GeForce RTX 50系列消费显卡,包括RTX 5090和RTX 5080等型号。其采用台积电4N工艺(而非数据中心的4NP),主要面向游戏和内容创作,搭载DLSS 4多帧生成等AI增强功能。
4.3 企业服务器
RTX PRO 6000 Blackwell Server Edition面向企业市场,提供最多6倍于上一代L40S的推理性能。Cisco、Dell、HPE、Lenovo、Supermicro等服务器厂商已经推出相关产品。
5 谁在用Blackwell?
Blackwell的采用方覆盖了AI产业链的几乎所有关键玩家:
- 云服务商:AWS、Google Cloud、Microsoft Azure、Oracle——为云客户提供Blackwell算力
- 前沿模型公司:OpenAI、Meta、xAI——用于训练下一代基础模型
- 科技巨头:Tesla(自动驾驶)、Meta(推荐系统)等
- 企业用户:通过RTX PRO服务器部署AI Agent、数据分析、科学仿真等工作负载
据报道,目前每周约生产1000个机架的Blackwell系统,供不应求仍是市场现状。
6 为什么Blackwell重要?
6.1 对AI行业
Blackwell使得训练和部署万亿参数模型成为现实。其FP4推理能力大幅降低了每token的推理成本,这对于让AI服务惠及更广泛用户至关重要。尤其是在"AI Agent"时代,推理工作负载的爆发式增长让高效率的推理芯片变得前所未有地重要。
6.2 对投资者
Blackwell的产能爬坡和需求情况是影响NVIDIA(NVDA)和台积电(TSM)业绩的核心变量。同时,Blackwell的制造涉及复杂的供应链:台积电4NP代工、SK海力士/美光的HBM3E内存、CoWoS封装产能等,这些环节都值得投资者关注。
6.3 对能源与基础设施
AI工厂的电力消耗——30倍能效提升意味着同等算力下显著降低电力需求。但由于总算力需求仍在指数级增长,数据中心电力和液冷基础设施仍是重要的投资主题。
7 Blackwell之后:NVIDIA路线图
NVIDIA已经宣布了"一年一架构"的发布节奏:
| 时间 | 架构 | 说明 |
|---|---|---|
| 2022 | Hopper | H100/H200,开启AI时代 |
| 2024 | Blackwell | B200/GB200,本文主角 |
| 2025 | Blackwell Ultra | GB300,引入NVFP4精度 |
| 2026 | Vera Rubin | 下一代架构,预计采用更先进工艺 |
这种快速迭代意味着每一代产品的生命周期更短,但也给投资者带来更可预测的业绩增长节奏。
8 总结
Blackwell不仅仅是一颗更快的芯片,而是NVIDIA"AI工厂"战略的基石。它通过双芯封装突破物理极限、通过FP4推理降低成本、通过第五代NVLink实现前所未有的规模化,重新定义了AI计算的性能边界。
对于关注科技和半导体板块的投资者而言,理解Blackwell的技术架构和产品布局是把握NVIDIA生态体系下一步走向的关键。
