
今天,我给自己的 Obsidian 做了一次大扫除。
清理掉了一批当时记录得热火朝天,但后来戛然而止的内容。看着这些“半途而废”的笔记,反而像在回看自己思路的进化史。其中最显眼的,是 2024 年 4 月关于 「大模型微调」 的系列记录。
当时的我,满腔热忱地想用专业知识去“训练”一个模型。
1. 2024年的执念:打造一个“数字同事”
在 2024 年 4 月 23 日的笔记里,我曾勾勒过一个朴素的愿景:
希望模型像一个刚入职的大学生。 它拥有极强的通用基础,但缺乏行业背景和业务逻辑。我当时坚信,“微调”是把它带进岗位的唯一路径,通过注入行业知识和规则,把它从一个通用模型演变为一个行业模型。
为了这个目标,我在 4 月 27 日配置了专门带英伟达显卡的独立电脑;5 月 8 日,我经历了环境配置、显存限制、数据清洗等一系列“折腾”后,终于让模型在本地跑了起来。
那种“掌控模型”的成就感,在当时看来就是技术的终点。
2. 判断的转向:微调不再是“默认路径”
然而,用现在的眼光回看,大模型生态的演进速度超出了所有人的预料。当我今天重新审视这些笔记时,我发现自己的核心判断已经发生了结构性位移:
- 能力溢出: 通用模型在代码、逻辑、甚至特定行业领域的深度,正快速逼近专家级,“非微调不可”的场景正在锐减。
- 工具重构: 随着 RAG(检索增强生成)、Agent(智能体)和 Workflow(工作流)的成熟,我们发现:很多时候不是模型能力不够,而是我们组织数据和任务的方式不够成熟。
微调,从当初人人标配的“入门必修课”,变成了一把特定场景下才需要动用的“重武器”。
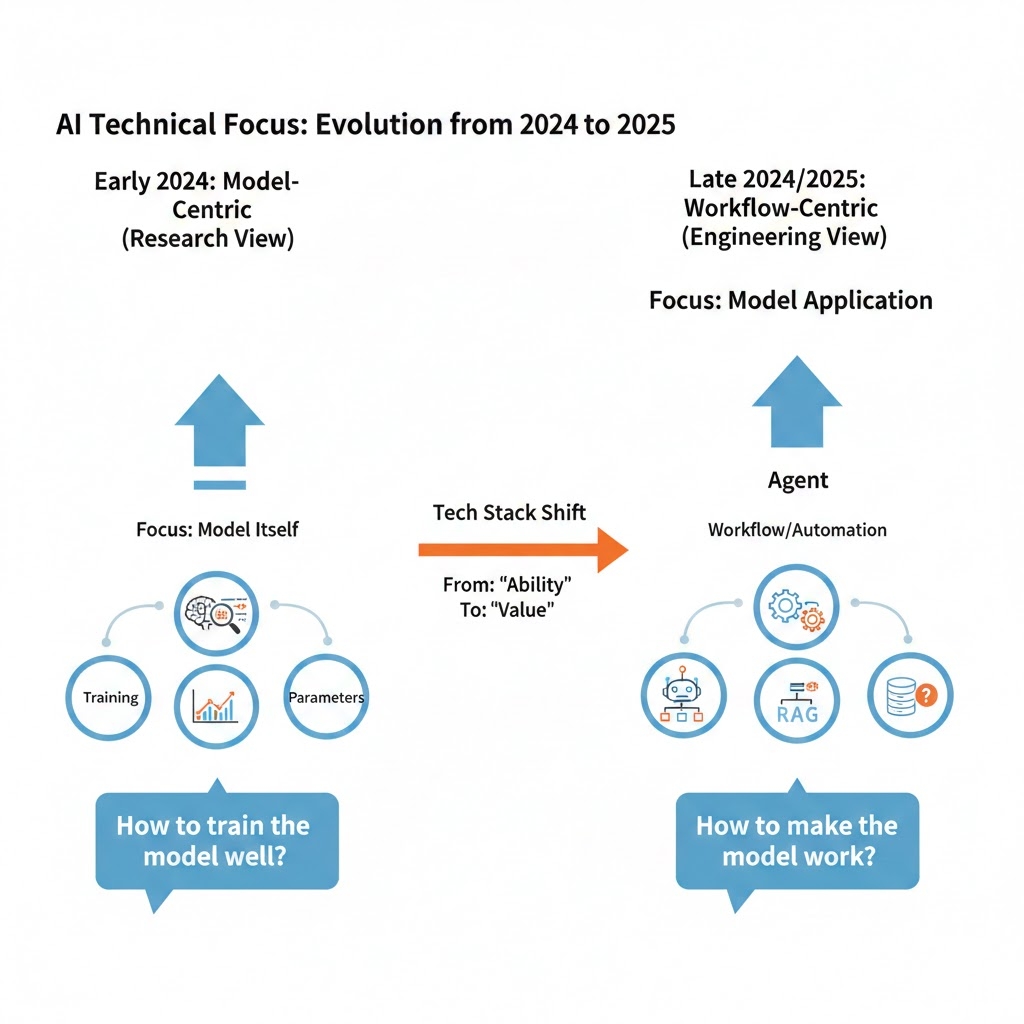
3. 从“能力”到“价值”:技术重心的迁移
删掉这些笔记,是因为它们已不再代表我现在的认知。整理这些记录,让我清晰地看到了这一年技术关注点的迁移路径:
| 维度 | 过去(2024年初) | 现在 |
|---|---|---|
| 核心关注 | 模型本身(参数、训练、微调) | 模型应用(Agent、自动化、系统化) |
| 研究视角 | 实验视角:怎么把模型训练好? | 工程视角:怎么让模型持续产出价值? |
| 解决路径 | 算力 + 数据 + 微调 | 提示词 + 工作流 + RAG |
| 最终目标 | 追求“模型能力” | 追求“业务结果” |
以前我关心如何给模型“大脑”做手术;现在我更关心如何给模型提供好用的“工具箱”和清晰的“标准作业程序(SOP)”。
4. 写在最后
那些被删除的笔记,如同阶段性探索结束的标志。
技术路线从来不是一条直线,而是一场不断自我否定的迭代。在 AI 时代,有些尝试会留下代码和模型,而有些尝试,其过程本身就是成果。
与其执着于驯化一个完美的模型,不如去构建一套能让模型发光发热的系统。
