
我在本地部署了一套基于Qwen3 4B小模型的沉浸式翻译系统,成功实现了不限量使用的AI翻译体验
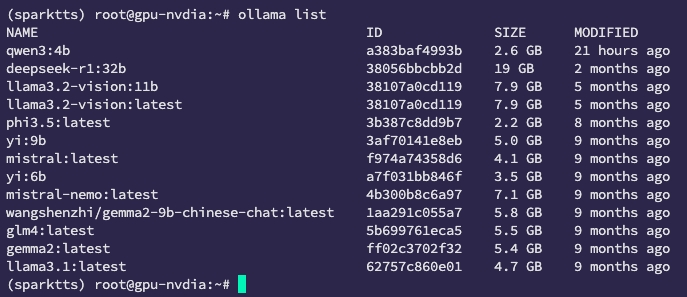
为什么选择Qwen3 4B?
相比更大的模型版本,Qwen3 4B在推理能力和资源消耗之间取得了不错的平衡。部署在一台普通的消费级GPU或高性能VPS上即可流畅运行,对于需要自建私有翻译服务的用户非常友好。
安装ollama 和open webui
安装过程这里就不赘述了,拉取qwen3:4b模型,在open webui中找到API密钥。
沉浸翻译中配置
配置自定义的API接口:
提升翻译速度: 在翻译提示中加入关键字 nothink,可以有效减少模型“思考”时间,从而提升响应速度,尤其在沉浸式逐句翻译中效果明显。这个关键词本身不会影响翻译结果语义,但会让模型更倾向于直接翻译而非进行逻辑扩展。

